
Datenbasierte Verwaltung: Eine Einordnung des Metatrends aus praktischer Sicht
Daten – der Rohstoff der digitalen Gesellschaft

Daten bilden den Rohstoff der digitalen Transformation in allen Lebensbereichen. Auch in der öffentlichen Verwaltung sind Daten unverzichtbar, um Entscheidungen auf eine gut fundierte Basis zu stellen und Dienstleistungen zu ermöglichen, die besser auf die Bedürfnisse der Bürgerinnen und Bürger eingehen.
Diese Sicht ist auch der Ausgangspunkt übergreifender Entwicklungen wie der Datenstrategie der Bundesregierung oder der Vorgaben der Bundesländer in ihren Digitalisierungs- und Informationszugangsgesetzen, die die die Bedeutung von Daten für die öffentliche Verwaltung unterstreichen (s. Abb. 1).
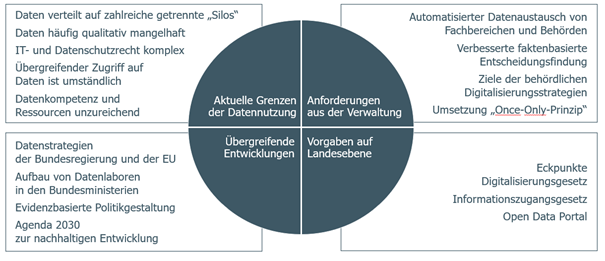
Aber auch interne Anforderungen aus der Verwaltung unterstreichen das Erfordernis einer grundlegend veränderten Art der Datennutzung (s. Abb. 1). Da es sich bei Daten um ein Arbeitsmaterial handelt, das sich durch seine Nutzung im Rahmen der originären Zweckbestimmung nicht „verbraucht“, ergibt sich die Möglichkeit, Daten aus verschiedenen Fachbereichen und Behörden für unterschiedliche Zwecke zu nutzen, zu teilen und zu verknüpfen.
Durch einen automatisierten Austausch von Daten oder – noch effizienter – deren Teilung auf einem von allen Akteuren gemeinsam genutzten Datenspeicher lassen sich auch Verwaltungsprozesse wesentlich vereinfachen und beschleunigen. Nicht zuletzt bilden die vorgenannten Optionen einer gemeinsamen Datennutzung durch unterschiedliche Dienststellen beziehungsweise Prozesse die Grundvoraussetzung für das ambitionierte Once-Only-Prinzip der digitalen Verwaltungstransformation in den nächsten Jahren (siehe Hintergrund: „Once-Only-Prinzip“).
Hintergrund: „Once-Only-Prinzip“
„Das Once-Only-Prinzip verfolgt das Ziel, dass Bürgerinnen und Bürger sowie Unternehmen notwendige Angaben nur noch ein einziges Mal an die Verwaltung übermitteln müssen. Mit dem Einverständnis der Nutzerinnen und Nutzer dürfen diese Daten für andere Anliegen später wiederverwendet werden, wenn dies notwendig ist.“ (Zitiert aus dem Leitfaden OZG Umsetzung.)
Trotz der zunehmenden Bedeutung von Daten und ihrer besonderen Eigenschaften, in denen so viel Potenzial für die Optimierung von Arbeitsabläufen und Prozessen liegt, ist die Nutzung der Daten in der öffentlichen Verwaltung noch immer sehr beschränkt. Doch welche aktuellen Grenzen innerhalb der Behörden verhindern eine synergetische Datennutzung?
Die größte Herausforderung liegt derzeit in der bewussten oder unbewussten Generierung von Datensilos (s. Abb. 1), die eine gemeinsame Nutzung oder einen übergreifenden Datenaustausch zwischen Fachverfahren und Behörden umständlich bis unmöglich machen. Zusammen mit einer häufig fehlenden Übersicht über vorhandene Daten (siehe Hintergrund: Was versteht man unter „Dark Data“?) erfordert die Datenerhebung und -verarbeitung einen immens hohen manuellen Aufwand.
Hintergrund: Was versteht man unter „Dark Data“?
Viele Daten werden als Zwischen- oder Endprodukte z. B. von Verwaltungsprozessen gespeichert, ohne die Potenziale zu nutzen, die diese Daten über ihren begrenzten Verwendungszweck hinaus bieten. Diese Daten, die hinsichtlich ihrer Nutzungsmöglichkeiten nicht „aus dem Schatten ihrer ursprünglichen Zweckbestimmung heraustreten“, werden als „Dark Data“ bezeichnet. Es ist ein zentrales Anliegen der datenbasierten Verwaltung, diese ungenutzten Daten aus ihrem „Dornröschenschlaf“ zu wecken.
Diese aktuellen Grenzen der Datennutzung in Kombination mit den externen und internen Treibern erzeugen einen umfassenden Handlungsdruck auf die Behörden zur Konzeption und Umsetzung einer datenbasierten Verwaltung.
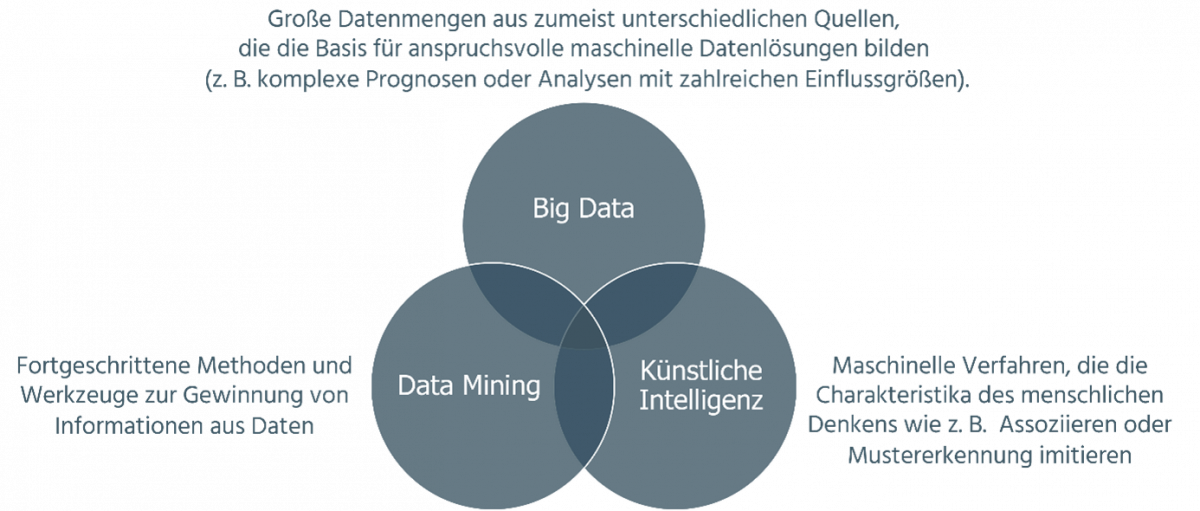
Ziel der datenbasierten Verwaltung ist es, mit neuen Methoden und Technologien alle für einen Entscheidungs- oder Planungsprozess einschlägigen Daten maschinell zu bündeln, aufzubereiten, zu analysieren und ggf. auch Interpretationshilfen bereitzustellen. Die Verzahnung verschiedener innovativer Konzepte aus aktuellen technologischen Metatrends eröffnet Behörden dabei völlig neue Perspektiven (s. Abb. 2).
Technischer Lösungsansatz
Ein konkretes Lösungskonzept, um diesen Herausforderungen zu entgegnen, sind sogenannte Daten-Hubs (s. Abb. 3 und Hintergrund: Was ist data[port]ai?), welche Daten aus unterschiedlichsten Quellen und in unterschiedlichsten Formaten (z.B. strukturiert aus Excel-Listen, aber auch unstrukturiert aus Textdateien, Bild- und Sensordaten) fachverfahrensübergreifend bündeln.
Der unmittelbare Vorteil einer solchen konsolidierten Datenbasis ist die Vereinfachung der Datenteilung zwischen internen und externen Stellen, da Medienbrüche behoben werden und manuelle „Datenverarbeitung“ reduziert wird.
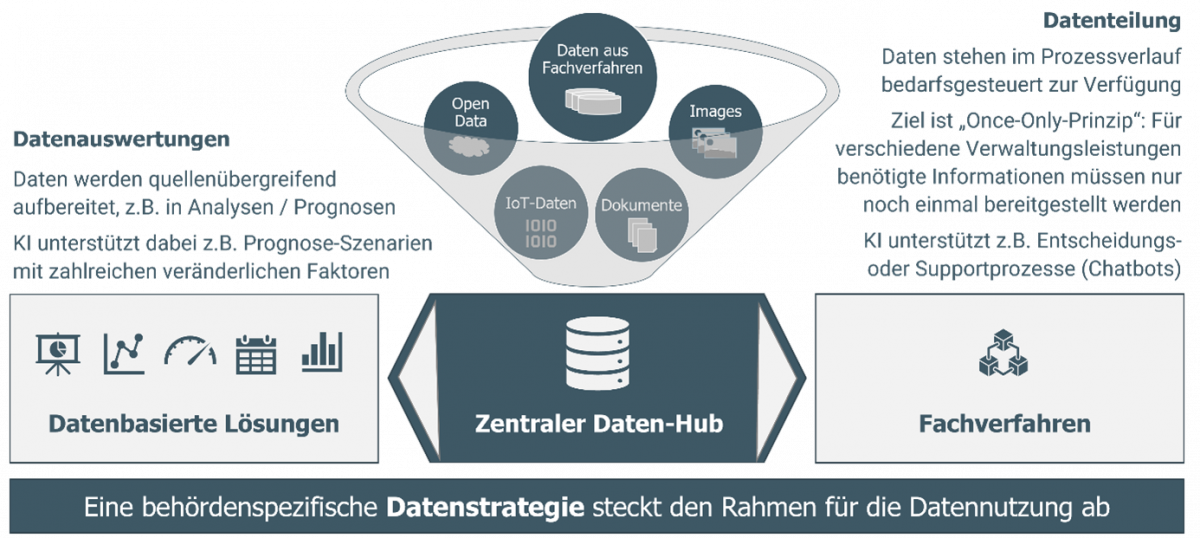
Das größte Potenzial ergibt sich jedoch durch das Aufsetzen verschiedenster statistischer Anwendungen auf die Daten-Hub-Infrastruktur zur Generierung von datenbasierten Lösungen (s. Abb. 3).
Hintergrund: Was ist data[port]ai?
Bei data[port]ai des IT-Dienstleisters Dataport AöR handelt es sich um einen Hub für Datennutzung und Künstliche Intelligenz. Er bündelt und erschließt Daten aus unterschiedlichsten Informationsquellen, um sie zur Nutzung bereitzustellen. Zusätzlich bietet data[port]ai für die Auswertung Methoden und Verfahren aus der Künstlichen Intelligenz. Durch data[port]ai eröffnen sich in den Bereichen Datenauswertungen und Datenteilung (zwischen unterschiedlichen Bedarfsträgern) völlig neue Möglichkeiten bei der Nutzung von Daten, dem wichtigsten Rohstoff der digitalen Transformation.
Das Motto von data[port]ai lautet vor diesem Hintergrund: Datensilos aufbrechen, maschinelle Datenteilung ermöglichen und Auswertungen für datenbasierte Entscheidungen bereitstellen.
Diese Anwendungen reichen von deskriptiven Analysen, wie sie typischerweise in Business Intelligence (BI)-Tools zu finden sind, bis hin zu KI-unterstützten Handlungsempfehlungen (s. Abb. 4 und Hintergrund: Datenauswertungen).
Dabei gilt die Faustregel: Je komplexer eine Analyse ist, desto größer ist auch ihr Mehrwert. Folglich wird der Mehrwert der zugänglich gemachten Daten vielfach erst durch die Anwendung von Methoden und Verfahren der Künstlichen Intelligenz optimal ausgeschöpft.
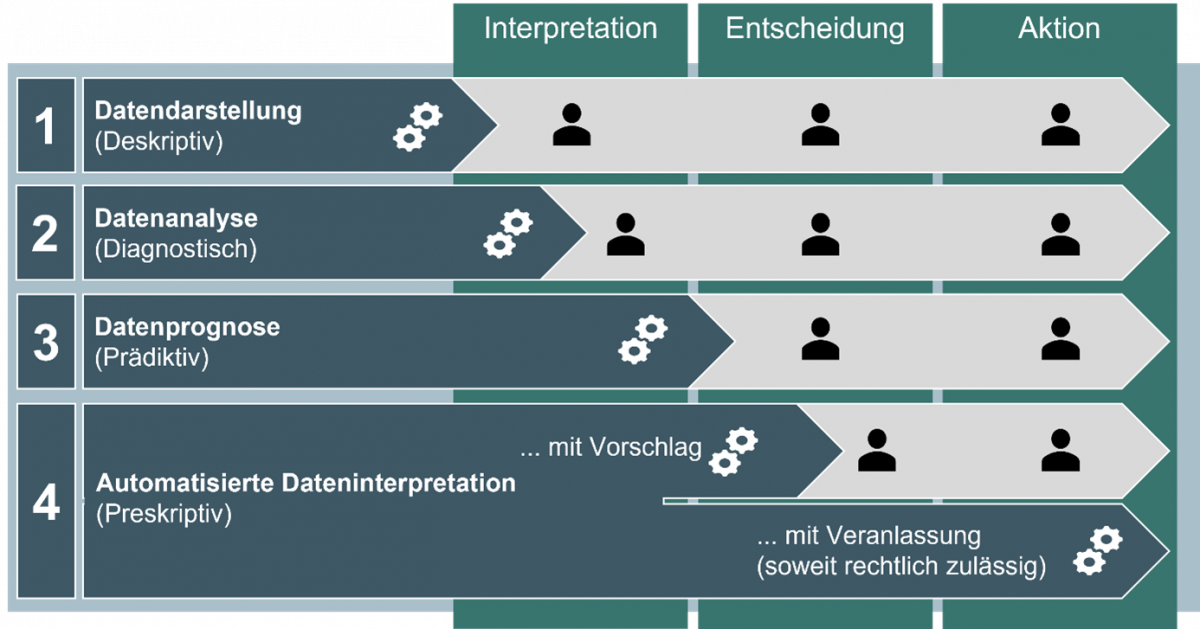
Hintergrund: Datenauswertungen
Die auf den Data-Hub aufgesetzten Anwendungen zur statistischen Datenauswertung kann man anhand der Komplexität ihrer Analysen unterteilen. Während bei den „deskriptiven Analysen“ Daten nur durch Tabellen, Kennzahlen und Grafiken übersichtlich dargestellt werden, kommen bei den diagnostischen, prädiktiven und preskriptiven Analysen bereits Verfahren des Maschinellen Lernens und des „Deep Learning“ zum Einsatz.
Verfahren des Maschinellen Lernens können dabei folgendermaßen unterschieden werden:
- Unüberwachtes Lernen („Unsupervised Learning“)
Benötigt Datenmaterial ohne vorher bekannte Zielwerte. Der Algorithmus versucht im Datenmaterial Muster zu erkennen, die vom strukturlosen Rauschen abweichen. Use Case Bsp.: Anomalieerkennung, einschließlich Betrugserkennung. Algorithmen Bsp.: k-means-Clustering, Principal Component Analysis
- Überwachtes Lernen („Supervised Learning“)
Benötigt Datenmaterial mit vorher klassifizierten Zielwerten (Trainingsdaten). Der Algorithmus analysiert die Trainingsdaten und erzeugt eine abgeleitete mathematische Funktion, die zum Abbilden neuer Beispiele verwendet werden kann. Use Case Bsp.: E-Mail Spam-Filter. Algorithmen Bsp.: Regression, kNN-Classification, Support Vector Machine
- Verstärktes Lernen („Reinforcement Learning“)
Benötigt kein vorheriges Datenmaterial, sondern generiert Lösungen und Strategien auf Basis von erhaltenen Belohnungen im Trial-and-Error-Verfahren. Use Case Bsp.: Autonomes Fahren. Algorithmen Bsp.: Monte-Carlo-Methoden, Temporal Difference Learning.
- Mehrschichtiges Lernen („Deep Learning“)
Diese am weitesten entwickelte Technik der Künstlichen Intelligenz orientiert sich an den komplexen neuronalen Strukturen des menschlichen Gehirns. Die Verarbeitung der Daten erfolgt dabei in einer Vielzahl verschachtelter Schichten aus einfachen Operationen, die jedoch in ihrer Kombination ein Interpretationsmodell ermöglichen, das sich mit jeder Nutzung selbst optimiert, um die Aussagequalität seiner Ergebnisse zu optimieren. Use Case Bsp.: Bilderkennung, z.B. Detektion von Straßenschäden. Algorithmen Bsp.: Neural Network
Neben den deutlich verbesserten Möglichkeiten der Auswertung von Daten zielt die datenbasierte Verwaltung auf die möglichst durchgängige Datenteilung zwischen Fachverfahren, Verwaltungsbereichen und Behörden (vgl. hierzu auch den Hintergrund: Datenteilung).
Hintergrund: Datenteilung
Daten-Hubs sind Datenspeicher, denen eine „Hub-and-Spoke-Architektur“ zugrunde liegt: Unterschiedliche Akteure tauschen dabei Daten nicht mehr unmittelbar untereinander, sondern mittels eines zentralen, gemeinsam genutzten, komplex strukturierten Datenspeichers, der sogenannten „Multi-Modell-Datenbank“.
Ein Daten-Hub verbindet viele verschiedene Datenquellen und -senken durch Datenreplikation bzw. „Publish-and-Subscribe Schnittstellen“ in Echtzeit. Die Replikation verwendet dabei bspw. CDC (Changed Data Capture), um die Daten auf dem Hub sofort zu aktualisieren, wenn Änderungen an den Datenquellen auftreten. Publish-and-Subscribe kann sowohl aus einer relationalen Datenbank als auch einer Datei, einer REST-API und lokalen oder Cloud-Anwendungen veröffentlichen und abonnieren.
Die Daten-Hubs fungieren dabei als Informationssystem mit allen für die Behördensicherheit erforderlichen Funktionen, wie bspw. Datenverfügbarkeit (HADR) oder Datenvertraulichkeit (Korrektheit, Vollständigkeit und Konsistenz von Daten). Die Werkzeuge zur Datenpflege (z.B. Anreicherung, Mastering, Harmonisierung) sind dabei bereits in die Daten-Hubs integriert.
Vorgehensmodell zur Umsetzung einer datenbasierten Verwaltung
Zur Umsetzung der Ziele einer datenbasierten Verwaltung muss eine Behörde zunächst klare Leitplanken für die Erhebung, Speicherung und Nutzung von Daten aufstellen. Dies geschieht zum einen durch die behördliche Digitalisierungsstrategie, die die digitalen Entwicklungsziele formuliert.
Operationalisiert werden diese Ziele hinsichtlich der benötigten bzw. verarbeiteten Daten durch eine behördenspezifische Datenstrategie, die den Rahmen für die Datenteilung und Datenauswertung absteckt. Damit ist die behördliche Datenstrategie gewissermaßen die „kleine Schwester“ der Digitalisierungsstrategie.
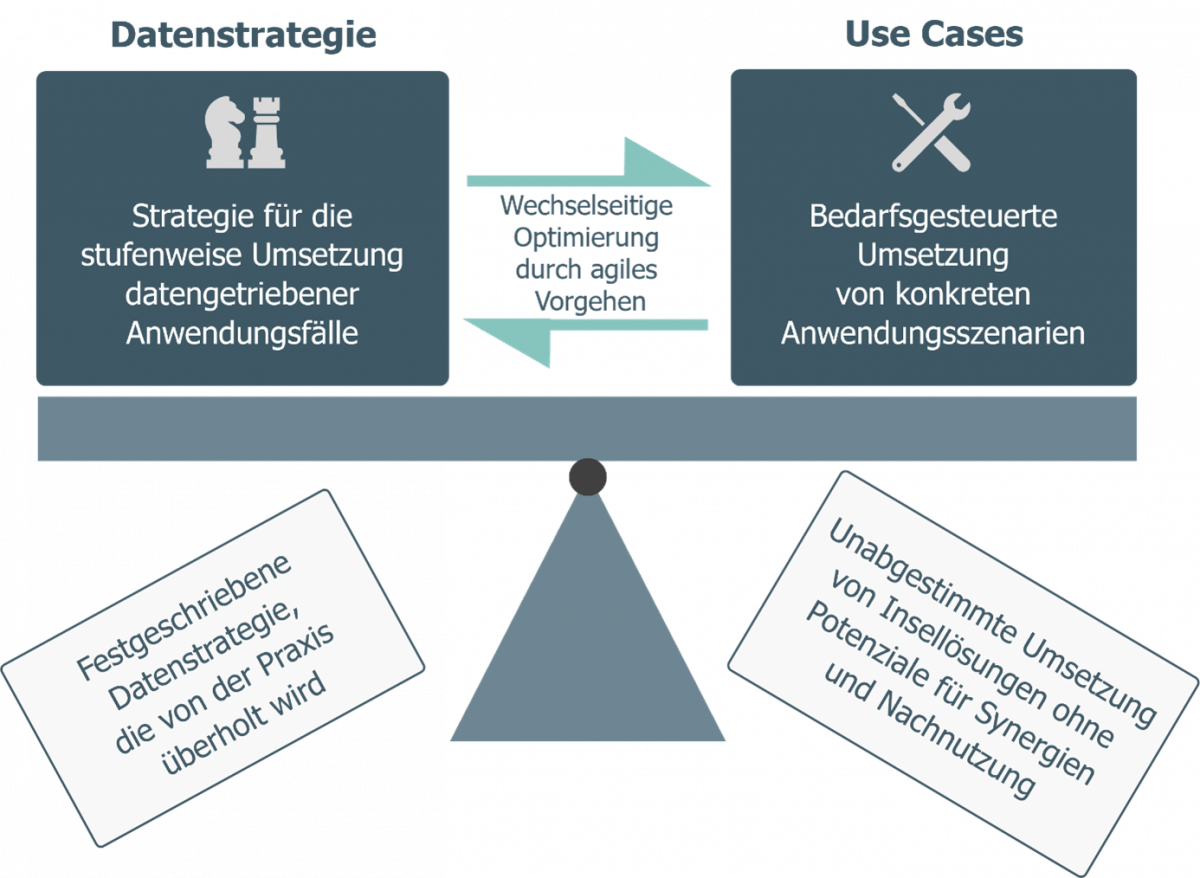
In der Praxis empfiehlt es sich, eine Datenstrategie nicht als ihrer Umsetzung vorgelagertes umfassendes Grundsatzpapier zu entwickeln. Deutlich erfolgsträchtiger ist es, datenstrategische Festlegungen ausgehend von eher grundlegenden Zielen anhand der Umsetzung konkreter datenbasierter Anwendungsszenarien zu detaillieren.
Im Idealfall verzahnt sich die Entwicklung bzw. Fortschreibung der behördlichen Datenstrategie mit der Umsetzung konkreter Anwendungsfälle („Use Cases“) in einem agilen Prozess derart, dass die vielfältigen Wechselbeziehungen zwischen „Theorie und Praxis“ eine optimale Berücksichtigung finden. (vgl. hierzu Abb. 5).
Ausblick
Die aktuell bereits verfügbaren technischen Lösungen für die datenbasierte Verwaltung unterstützen eine stimmige Strategie für die Erhebung, Aufbereitung und Nutzung von Daten der Kommunalverwaltung und bieten im Ergebnis eine konsolidierte Datenbasis für faktenbasierte Planungen und Entscheidungen, aber auch als Grundlage für Open Data und Verwaltungsprozesse mit einem hohen Digitalisierungs- und Automationsgrad.
Damit ergeben sich auch für Behörden neue Optionen für zukunftsweisende digitale Lösungen, die den digitalen Wandel unserer Verwaltungen deutlich vorantreiben werden.




