

In der Privatwirtschaft ist der Wert von Daten und datengetriebenen Geschäftsmodellen längst erkannt und teilweise etabliert. In Wissenschaft und Forschung sind datengetriebene Analysen, algorithmenbasierende Entscheidungsunterstützungen oder schlicht die Bereitstellung von Forschungsdaten für Dritte längst wissenschaftliche Praxis geworden. Nun folgt ein Forschungsdatengesetz, um Zugänge und Standards stärker zu definieren und die Informationen niederschwelliger verfügbar zu machen. Das Dateninstitut, das die Bunderegierung derzeit etabliert, soll sektorübergreifend koordinieren und eine zentrale Vernetzungseinheit bilden. Daran schließen sich die unterschiedlichen Initiativen zu Open-Data an. In der gesamten EU sollen sogenannte High-Value-Datasets in den Bereichen Georaum, Erdbeobachtung und Umwelt, Meteorologie, Statistik, Unternehmen und Mobilität offen zur Verfügung gestellt werden.
Auch im Bereich der Verwaltung gewinnen datengetriebene Anwendungen zunehmend an Bedeutung. Die Bundesregierung hat zuletzt wesentliche Schritte der Datenstrategie umgesetzt; so wurden Datenkoordinatoren ernannt und Datenlabore eingerichtet. Sowieso sind daten- oder algorithmenbasierende Anwendungen im Öffentlichen Sektor in vielen Bereichen bereits der Standard. Das gilt in der IT-Sicherheit, bei Büroanwendungen oder ganz besonders bei Anwendungen von Behörden mit Sicherheitsaufgaben, bspw. in der Aufklärung oder Forensik.
Letztlich zeigt der Bereich des originären Verwaltungshandelns, sprich in den einzelnen Fachanwendungen bzw. fachanwendungsübergreifend, aktuell die größten Potenziale. Noch immer liegen viele Daten in spezifischen Formaten innerhalb der eigenen Umgebungen einzelner Fachanwendungen. Der Föderalismus führt nicht selten dazu, dass sogar Daten der grundsätzlich gleichen Fachanwendungen in zig unterschiedlichen Rechenzentren einzeln und abgeschirmt verharren. Diese unangetasteten Datensilos liegen in unstrukturierter Form vor und können technisch und organisatorisch bisher nur unzureichend eingebunden werden. Im Zweifel bedarf es bei Abfragen oder Migrationen aufwändiger manueller Datenpflege. Daten werden einzeln kuratiert, aufbereitet und konvertiert.
Dabei gibt es bereits etablierte Lösungen, die an diesen Stellen anknüpfen. Softwaretools die Datensilos aufbrechen, unterschiedliche Formate automatisch einlesen und die Daten nutzbar machen. Tools zur Analyse und Kombination von Datenpunkten zu den validen Informationen oder zur Visualisierung.
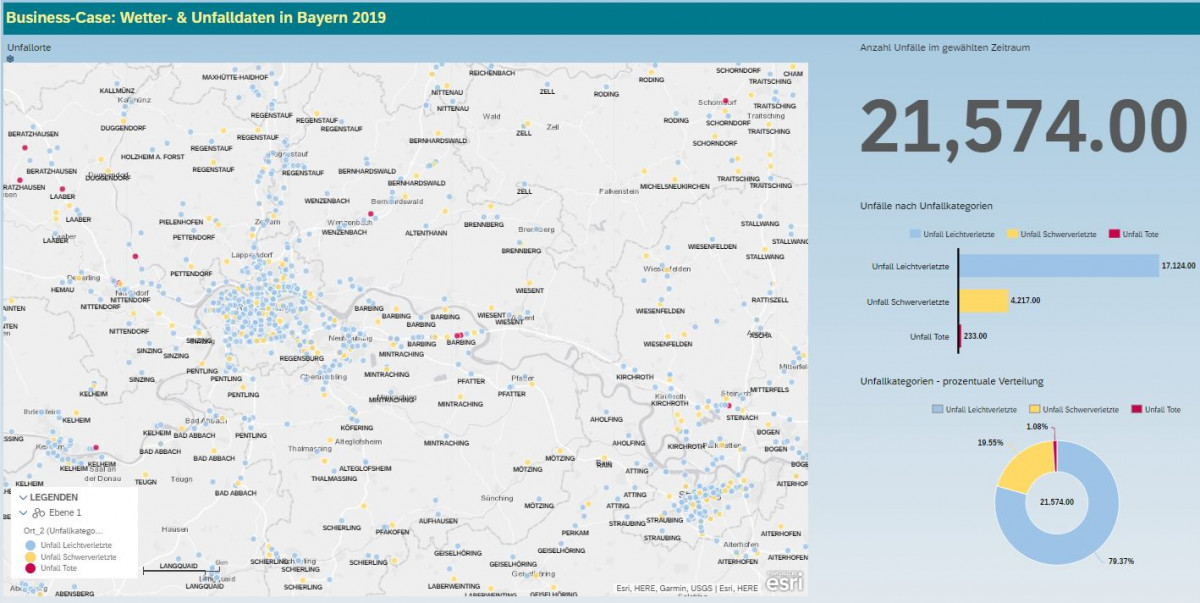
Ein gutes Beispiel war der SVA Workshop zu SAP Analytics, der einen solchen High-Value-Datensatz zu Unfall- und Wetterdaten als Ausgangspunkt genommen hat. Innerhalb eines Workshoptages konnten die Teilnehmerinnen und Teilnehmer ohne besondere Vorkenntnisse erste Ergebnisse ableiten. Die folgenden beiden Abbildungen veranschaulichen, wie durch die grafische Aufbereitung der Daten eine hohe Informationsdichte und Aussagekraft erzielt werden kann.
Die Analyse der Daten auf ihrer jeweiligen Ebene stellt keine hohe Anforderung dar, da jedes Dataset in sich ein Alleinstellungsmerkmal aufweist (Abbildung 1).
Die Synchronisierung unterschiedlicher Datasets variiert in ihrer Effektivität in Abhängigkeit zu ihren Schlüsselmerkmalen. In diesem Prozess wurden die Daten automatisiert kuratiert, aufbereitet und in das gewünschte Format konvertiert. Mittels automatisierter Prozesse ließen sich diese Datasets synchronisieren (Abbildung 2).




