DeepSeek: Alternative oder trojanisches Pferd?
Wie mangelnde Digitalkompetenz KI zur Gefahr werden lässt


Am 10. Januar 2025 veröffentlichte DeepSeek einen freien ChatBot zu seinem LLM V3 und löste damit ein “Börsenbeben” unter verschiedenen, vorwiegend US-Technologiewerten aus. Grund dafür waren die behauptet deutlich geringeren Kosten bei gleichzeitig hoher Qualität des Sprachmodells. Dieser Hype basiert allerdings auf einigen Fehlinformationen: Das Modell tauchte nicht aus dem Nichts auf. Bereits im Laufe des Jahres 2024 wurde V2 veröffentlicht, im November eine Pre-Version von V3.
Das neueste DeepSeek Release R1 basiert auf V3, dient aber "complex reasoning", wie etwa mathematischen Problemen.
Nicht das Large Language Model als solches, sondern nur eine der Chatbot-Varianten ist gratis; auch die APIs für die Chatbots von Drittanbietern (ein wesentliches Element im Geschäftsmodell von LLM) sind kostenpflichtig. Außerdem beziehen sich die kommunizierten Entwicklungskosten von 5,5 Mio. USD nicht auf das Gesamtmodell, sondern nur auf die letzte Phase des Trainings.
Ist DeepSeek wirklich kostengünstiger?
Zutreffend ist aber, dass DeepSeek durch seine Architektur massiv an Ressourcen sparen kann. Ein Beispiel: Ein LLM speichert Wissen in Clustern, deren Punkte über Vektoren in einem n-dimensionalen Raum definiert sind; dies kann für Wörter, Sätze oder ganze Texte geschehen. ChatGPT-3 hatte beispielsweise einen Raum von 175 Mrd. Dimensionen, ChatGPT-4 mutmaßlich von 1,8 Billionen Dimensionen. Abfragen erfolgen gegen diese Cluster, wobei zumindest die relevanten Teile des LLM im (teuren) Hauptspeicher geladen sein müssen, also in-memory, so wie etwa auch die Hana-Technologie von SAP. Es sind diese Erfordernisse, die Training und Betrieb eines LLM so ressourcenaufwändig machen.
Wenn nun ein Cluster von Wissensrepräsentationen nicht durch die einzelnen Vektoren der Punkte im Cluster, sondern durch einen dimensionsreduzierten, aber die Bedeutung im Wesentlichen erhaltenden latenten Vektor repräsentiert werden kann, erspart man sich massiv teuren Hauptspeicher und macht das Modell ressourcensparender und damit billiger in der Abarbeitung. Klug gestaltet hält sich dabei der Wissensverlust in Grenzen. Durch diese und andere Innovationen kann das Modell in der VR China bereits seit einiger Zeit zu einem wesentlich günstigeren Preis angeboten werden als die der Konkurrenten.
Nicht alle Fragen werden beantwortet
Bereits kurz nach der Veröffentlichung ergaben sich vor allem zwei Bedenken: ein mögliches Bias im LLM und das Sammeln von Nutzerdaten durch das kommunistische Regime der Volksrepublik China. Einige Elemente des Bias im DeepSeek LLM sind sofort ersichtlich.
Der Unterschied in der Behandlung politisch unangenehmer Fragestellungen zwischen ChatGPT und DeepSeek ist offensichtlich.
Bild 2 am Ende des Artikels zeigt die Antwort auf eine für die VR China unangenehme Frage, die offenbar nicht beantwortet werden soll. Das LLM beginnt dabei mit einer – soweit ersichtlich – durchaus sinnvollen Antwort und bricht dann abrupt mit den gezeigten Meldungen ab. Bild 3 zeigt andererseits die Reaktion von ChatGPT auf ein Thema, das aus US-Regierungssicht möglicherweise nicht beantwortet werden soll. Hier wird allerdings eine offenbar neutrale Darstellung der Ereignisse gebracht (der Screenshot stellt nur den ersten Absatz dar). Der Unterschied in der Behandlung politisch unangenehmer Fragestellungen zwischen ChatGPT und DeepSeek ist offensichtlich.
Wesentlich bedenklicher als derartige, doch etwas plumpe Maßnahmen sind andere Wege der Beeinflussung. Eine elegante und wohl auch sehr unauffällige Weise, einem LLM ein Bias zu vermitteln, ist die Einschränkung der Lernbasis. Ein plakatives Beispiel: Wird als Lernbasis in den USA für die Verteilung der verhafteten Mordverdächtigen nach “Race, Gender and Age” der Bundesstaat New York ausgewählt, so ergibt sich eine Dominanz schwarzer Täter. Dieselbe Statistik aus Everett (Washington) ergibt hauptsächlich weiße Täter. Die im AI-Act geforderte Offenlegung der Algorithmen geht hierbei vollkommen ins Leere, da das Bias nicht im Algorithmus steckt. In westlichen Unternehmen ist derartiges dank Compliance-Vorschriften und Whistleblower-System wohl zumindest massiv erschwert bzw. kommt es früher oder später ans Tageslicht. Wie sich dies in der Volksrepublik China darstellt, bleibt abzuwarten. Dass DeepSeek als Open Source bezeichnet wird, ändert daran nichts, da die Lernbasis gerade nicht offengelegt wird.
Diese Beeinflussung kann jedenfalls weit über den Bereich der Politik hinausgehen; Beispiele wären manipulierte Antworten auf Fragen zur Technologieführerschaft in der Batterietechnik, die Frage nach der besten Suchmaschine, die Bewertung von Onlinehändlern u.v.a.m. Diese Antworten können auch bezahlt werden – eine sehr effektive „Werbung“.
Gibt es in der VR China Datenschutz?

Ein weiteres Problem ist der Schutz persönlicher Daten, wobei die italienische Datenschutzbehörde den Zugang zu DeepSeek aus genau diesem Grund gesperrt hat. Bei allen Bedenken über die Wirksamkeit derartiger Sperren ist dies dennoch ein starkes Signal. Auch die US Navy hat ihren Angehörigen die Nutzung verboten. Welche Datenschutzprobleme sind beim LLM nun generell möglich?
Bei bezahlten Accounts ist der Nutzer jedenfalls zuordenbar, selbst bei Nutzung ohne Account kann ein Tracking mit verschiedenen Methoden vorgenommen werden. Betroffen sind sowohl der Inhalt der Abfragen wie auch die Metadaten dazu. In beiden Fällen können Profile angelegt werden – allgemein oder personenbezogen. Das vermutlich größte Problem ist die Eingabe sensibler Daten in den Chatbot. Dies sollte der Nutzer eigentlich generell unterlassen, da diese Daten grundsätzlich in das LLM als Lernmaterial eingehen können. Allerdings kann beispielsweise ein europäischer ChatGPT-Nutzer ein entsprechendes Opting-out wählen, bei Firmenaccounts ist dieses Opting-out im Gegensatz dazu sogar Voreinstellung.
Welche Nutzerdaten – persönliche Accountdaten, Chat- und Metadaten – DeepSeek wie verwendet, ist hingegen nicht bekannt und dies ist wohl der Grund für die Sperre durch die italienische Datenschutzbehörde. Ein weiteres Thema sind Tracking-Methoden (beispielsweise Tracking Cookies oder Fingerprints), die das Nutzerverhalten bei ganz anderen Applikationen mitprotokollieren. Gerade Fingerprinting, bei dem ohne Cookie ein Software- und Hardwareprofil erstellt und wiedererkannt wird, lässt sich nutzerseitig schwer erkennen bzw. abstellen. Die Privacy Policy von DeepSeek jedenfalls ist zu diesem Thema eher wortkarg. Im Gegensatz zu ChatGPT wird auch nicht expliziert, ob und unter welchen Umständen die Nutzerdaten in das Training des Systems eingehen. Interessanterweise zeichnet DeepSeek auch “keystroke patterns or rhythms” auf, den Autoren erscheint nicht ganz ersichtlich, wofür dies geschieht. Alle Daten werden jedenfalls in der VR China gespeichert, worauf in der Privacy Policy auch explizit hingewiesen wird.
Fazit: Nichts für digital wenig kompetente Nutzer
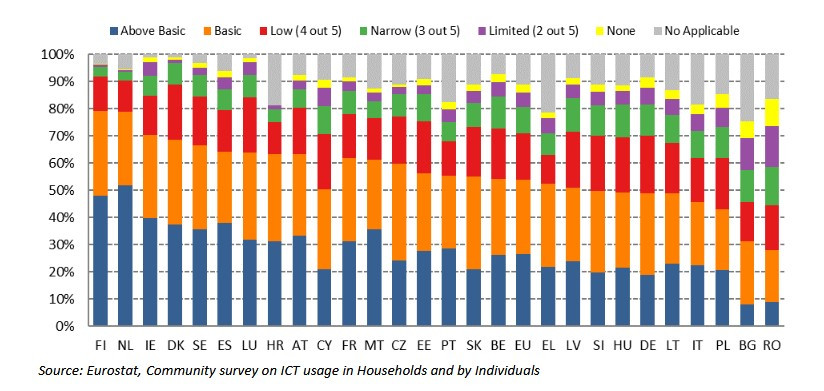
Zusammenfassend kann gesagt werden: DeepSeek bringt einige interessante technologische Neuerungen, gerade im Bereich Rechnereffizienz und Kosten. Das System ist aber erkennbar von einem Anbieter eines diktatorisch regierten Staates und die Datenschutzeinstellungen sind intransparent sowie ihre tatsächliche Einhaltung zweifelhaft. In Summe besteht somit für deutsche Nutzer – gerade auch im Behördenumfeld – kein besonderer Anreiz dieses System zu nutzen, zumindest, solange die Bedenken nicht ausgeräumt sind. Noch dazu in einem Land, in dem die Digitalkompetenzen in der Breite nicht sonderlich ausgeprägt sind, wie Eurostat im Auftrag der Europäischen Kommission belegt (Bild 1). Weniger als 20 % der Deutschen haben digitale Kompetenzen über dem Durchschnitt, das ist einer der schlechtesten Werte in der Europäischen Union. Und für den sachgerechten Umgang mit solchen Tools im professionellen Umfeld wären wohl eher weit über dem Durchschnitt liegende Digitalkompetenzen erforderlich.
In diesem Zusammenhang sei auf Art 4 des AI Act verwiesen:
Die Anbieter und Betreiber von KI-Systemen ergreifen Maßnahmen, um nach besten Kräften sicherzustellen, dass ihr Personal und andere Personen, die in ihrem Auftrag mit dem Betrieb und der Nutzung von KI-Systemen befasst sind, über ein ausreichendes Maß an KI-Kompetenz verfügen [...].
Dieser Passus trat übrigens gerade eben am 2.2.2025 in Kraft (Art 113 lit a).
Bildquellen